-------------------------
02.Variable_Operator
-------------------------
1. 파이썬 프로그래밍의 구성 요소
1) Literal : 사용자가 직접 입력하는 데이터
2) Variable : 데이터에 붙이는 이름
3) Function : 독립된 메모리 공간을 할당받아서 한 번에 수행되는 코드 블록
4) Class & Instance : 동일한 목적을 달성하기 위해 모인 데이터와 기능의 집합
5) Module : 파이썬에서는 파일을 모듈이라고 한다.
6) Package : Module의 집합으로 배포 단위
7) Comment : 번역하지 않는 문장으로 #으로 시작
2. 코딩 시 주의 사항
=> 라인 단위로 번역해서 실행하기 때문에 기본적으로 세미콜론(;)은 필요없지만, 한 줄에 2개의 실행문(=이 존재하는 문장이나 함수 호출)이 있는 경우에는 세미콜론(;)으로 구분한다.
=> 파이썬은 하나의 블록을 만들 때 들여쓰기를 이용한다. -> 기본 형태는 빈 칸 네 개이지만, 일정하게 맞추기만 하면 된다. -> 같은 블록인데 들여쓰기를 맞추지 않으면 동작 시 에러가 발생한다.
=> 하위 레벨을 만들 때는 콜론(:)다음에 들여쓰기를 하고 작성한다.
=> 콘솔에 출력할 때는 print함수를 이용하는데 여러 개를 출력하고자 하면 콤마(,)로 구분한다.
=> 기본적으로 print()는 줄 바꿈(\n)을 제일 마지막에 수행합니다.
3. Comment(주석)
=> # 다음에 작성하면 주석이 됩니다.
=> 파이썬에서는 문자열 상수를 만들 때 작은 따옴표(' ')나 큰 따옴표(" ") 안에 묶고, 여러 줄의 경우는 작은 따옴표나 큰 따옴표를 3번 사용해서 만든다.
ex. """Hello World"""
주석을 만들고자 할 때에도 내용에 큰 따옴표나 작은 따옴표를 3번 사용해서 만들기도 합니다.
-> 대신 이 안에 강조를 위하여 큰 따옴표나 작은 따옴표를 하고 싶으면, 안과 밖에 서로 다른 따옴표를 사용해야 합니다.
=> #!는 주석이 아니고 유닉스의 shebang입니다.
파이썬에서는 소스 코드의 인코딩을 표시할 목적으로 사용
4. Document 관련 명령어
=> dir(데이터) : 데이터가 호출 가능한 속성과 메서드를 리턴
=> help(함수나 메서드) : 함수나 메서드의 도움말을 출력
List, Tuple, Dictionary의 특징 : https://gostart.tistory.com/58
리스트(List)
-> 인덱스는 0부터 시작한다.
튜플(Tuple)
-> 생성하고 나면 값을 삭제하거나 변경할 수 없다.
-> 속도가 빠르다.
디셔너리(Dictionary)
-> KEY와 VALUE로 구분되며 KEY를 통해 VALUE에 접근이 가능하다.
-> 리스트나 튜플처럼 인덱스를 통해 값에 접근할 수 없다.
-> 동일한 Key 자료는 존재할 수 없다.
5. Python의 Keyword(예약어)
=> python이 기능을 정해둔 것으로 다른 용도로 사용하면 에러가 발생한다. -> 예약어를 변수의 이름이나 함수의 이름으로 사용할 수 없다.
=> 확인하는 방법 :
import keyword
print(keyword.kwlist) # keyword.kwlist : 파이썬에서 사용하는 키워드 목록을 조회하는 명령어
=> 에러 :
None = 20 # 위의 과정에서 None이 예약어임을 확인하였다. -> None에 다른 데이터를 대입할 수 없습니다.
6. 모듈을 찾아오는 순서 확인
import sys
print(sys.path) # sys.path : 모듈을 가져올 때(import sys) 찾아야 할 경로를 저장해 둔 목록
깨알) Pycharm에서 빨간색 단추(점)는 디버깅 포인트이다. 단추의 위치까지 실행하며, 빨간색 단추를 한 번 더 클릭하면 단추를 제거할 수 있다.
7. 파이썬의 기본 자료형
숫자 데이터 : int(정수), float(실수), complex(복소수) - 하나의 데이터(scala data), 불변(immutable), 직접 접근
직접 접근은 데이터의 이름이 실제 데이터를 의미하는 것을 말한다.
ex. a = 10 : a가 아니라 10이다.
str(문자열) : 0개 이상의 문자의 집합, 불변, 순차 접근
tuple(튜플) : 0개 이상의 데이터의 모임, 불변, 순차 접근
list(리스트) : 0개 이상의 데이터의 모임, 가변, 순차 접근
-> tuple과 list의 차이점은 데이터의 수정이 가능하느냐에 있다.
set(집합) : 0개 이상의 데이터의 모임, 가변, 순차 접근 불가
-> 순서대로 저장되어있지 않다.
dict(사전, 디셔너리, map, hashtable 등) : 0개 이상의 데이터의 모임, 가변, KEY - VALUE 시스템
-> KEY가 set(집합)으로 만들어져 있다.
VALUE에는 똑같은 데이터가 존재할 수 있지만, KEY에는 똑같은 데이터가 존재할 수 없다.
-> KEY는 중복이 불가능하다.
-> list는 dict를 속도 면에서 절대 이길 수 없다. 그러나 dict는 메모리의 낭비가 심하다는 단점이 존재한다.
dict를 사용하여 속도 면에서 이득을 보려고 하면, 메모리의 낭비가 발생한다.
dict를 잘 기억해두자!
8. Literal
=> 사용자가 직접 입력하는 데이터로, 처음 사용될 때 static한 영역에 생성되고 이후부터는 재사용을 합니다.
ex. a = 10, b = 10이면 10을 두 개(a, b)가 참조하는 것이지 저장이나 대입을 하는 것이 아니다.
=> 숫자
정수(int) : 10진수(숫자), 8진수(0o숫자), 16진수(0x숫자), 2진수(0b숫자), 숫자L
실수(float) : 1.2, 0.12e1(0.12 * 10의 1승)
복소수(complex) : 4+5j
=> bool : True 와 False (첫 글자가 대문자)
=> str : 작은 따옴표나 큰 따옴표 안에 기재하면 되는데 여러 줄은 작은 따옴표나 큰 따옴표 3번으로 나타낸다.
=> bytes : 바이트의 집합으로 b'문자열' 또는 b'\코드\코드...'
=> list : [ ]안에 나열
=> tuple : ( )안에 나열
=> set : { }안에 나열
=> dic : {key:value, key:value, ...}
str, bytes, list, tuple, set, dict 는 for를 이용하여 순차적으로 접근이 가능하다고 해서 iterable(반복가능한 객체)이라고 합니다.
=> 제어문자 : \다음에 영문 1글자를 기재해서 특별한 명령을 수행하도록 하는 문자
\n : 줄 바꿈
\t : 탭
\\, \', \"
=> None : 가리키는 데이터가 없다라는 의미
null이라고 하기도 하고 자료구조에서는 nil이라고 하기도 하며 데이터 분석 라이브러리에서는 NaN도 유사한 의미로 사용
9. 사용자 정의 명칭 - identifier
=> 데이터, 함수나 메서드, 클래스, 인스턴스, 모듈, 패키지에 부여하는 이름
=> 영문자, 숫자, 한글, _ 등을 사용할 수 있음
-> 시작은 문자로, 중간 공백은 불가능하다.
=> 에약어는 사용자 정의 명칭으로 사용할 수 없습니다.
=> 일반적으로 클래스 이름만 대문자로 시작하고 변경할 생각이 없는 데이터의 이름은 모두 대문자로 만드는 것이 관례
10. Variable(변수)
=> 변수는 데이터에 이름을 붙이는 것
이름 = 데이터(리터럴 또는 다른 변수 또는 함수)
이름이 존재하지 않으면 이름을 생성하고 이름이 존재하면 가리키는 곳을 변경합니다.
데이터를 가리킬 때 자료형이 결정됩니다.(Dynamic Binding)
ex. int(자료형) 이름 : 정적(static)바인딩
Value : 값을 저장, 빠르다.
Reference : 참조를 저장, 느리다. Dynamic Binding이 가능하다.
=> 이름을 만들 때는 기억하기 쉬운 이름 또는 의미를 파악하기 좋은 이름을 사용하는 것이 좋습니다.
=> 변수는 기본적으로 자신의 영역이 종료되면 파괴되지만 강제로 파괴하고자 하는 경우는 del 변수명
del을 사용하는 이유 -> heap의 공간을 재사용하기 위해서
null = \0
[1,2,"3"] -> 불가능한 것이 아니라 숫자와 문자는 비교가 불가능하기 때문에 사용하지 않는 것이다.
=> 하나의 데이터를 저장하는 경우에는 이름이 데이터를 의미하지만 0개 이상의 데이터를 저장하는 경우에는 이름은 시작위치를 의미합니다.
=> 영역이 다른 곳에서 이름을 만들면 동일한 이름으로 변수를 생성할 수 있습니다.
11. Operator(연산자)
=> 연산을 수행해주는 부호나 명령어
산술 연산 : 숫자 데이터를 연산해서 숫자로 결과를 리턴하는 연산
논리 연산 : bool 데이터를 연산해서 결과를 bool로 리턴하는 연산
단항 연산(unary) : 데이터의 개수가 1개인 연산
이항 연산(binary) : 데이터의 개수가 2개인 연산
1) 할당(assignment) 연산자
= : 오른쪽의 데이터의 참조를 왼쪽의 변수에 대입
2) 산술 연산자
+ : 숫자의 경우는 덧셈을 하고 데이터의 모임은 결합
파이썬에서 다른 종류의 데이터끼리는 덧셈 연산이 안된다.
- : 뺄셈
* : 숫자 데이터의 경우는 곱셈이고 데이터의 모임과 정수의 경우에는 반복
** : 거듭 제곱
/ : 나눗셈
// : 몫만 구해주는 것
% : 나머지
3) 비교 연산자
=> 연산의 결과를 bool 로 리턴
>, >=, <, <=
==, !=
=> bool 데이터도 크기 비교가 가능
True는 1로 간주하고 False는 0으로 간주하기 때문에 True가 False 보다 크다.
=> 문자열도 크기 비교 가능
첫 글자부터 코드 값을 비교해서 크다, 작다를 판별한다.
대문자 A는 65
소문자 a는 97
4) 산술 비트 연산자
=> 정수 데이터를 2진수로 변환해서 각 비트 단위로 연산을 수행한 후 10진 정수로 결과를 리턴하는 연산자
& : and로 둘 다 1일 때만 결과가 1이고, 나머지 경우는 0
| : or로 둘 다 0인 경우만 0이고, 나머지 경우는 1
=> 2개의 연산자는 데이터 분석을 위한 라이브러리(numpy)의 데이터 모임에서도 사용이 가능한데 이 경우는 위치 별로 연산을 수행해서 리턴
^ : eXclusive OR(XOR)로 두 개 데이터가 같은 경우는 0 다른 경우는 1
~ : 단항 연산으로 1의 보수
<< : 왼쪽으로 미는 연산자 - 곱하기 2
>> : 오른쪽으로 미는 연산자 - 나누기 2
10진수 -> 2진수 변환
ex. -20 -> ?
20을 먼저 2진수로 바꾸어준다.
몫이 0이 나올 때까지 나누어줘야 한다. (맨 아래가 0)
20 -> 0000 0000 0001 0100으로 나타난다.
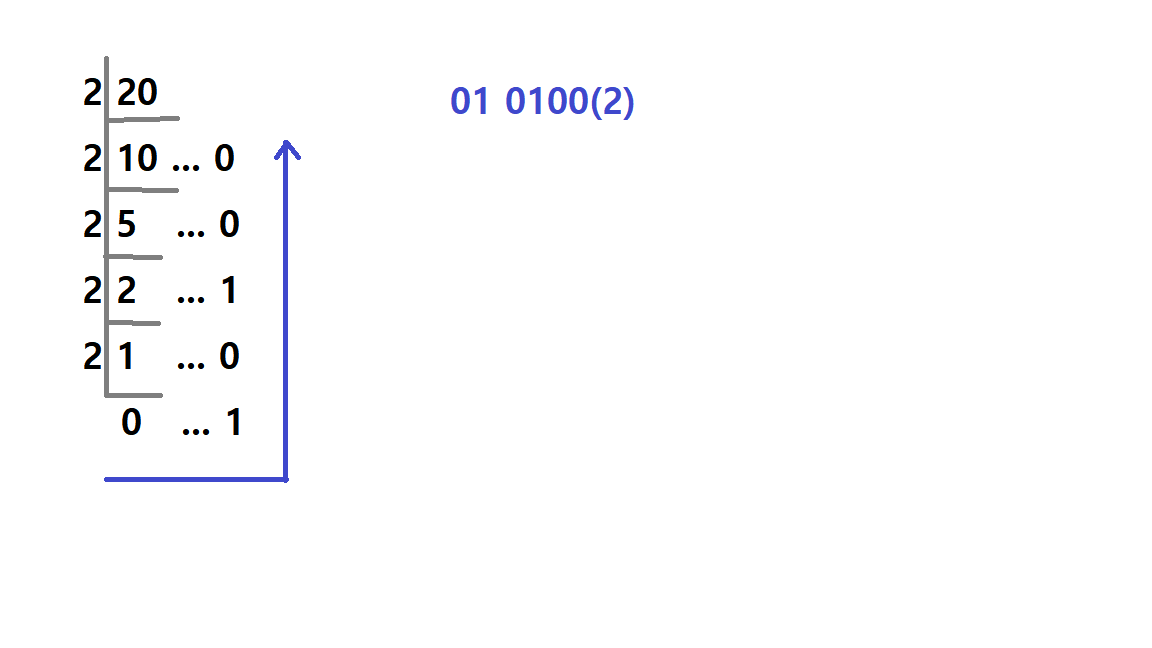
20을 2진수로 나타낸 값에 1의 보수를 취해준다.
0000 0000 1110 1011 -> 1111 1111 1110 1011
1의 보수를 취한 값에 마지막으로 2의 보수를 취해준다.
1111 1111 1110 1011 + 1 -> 1111 1111 1110 1100
ex. 17 -> 0000 0000 0001 0001
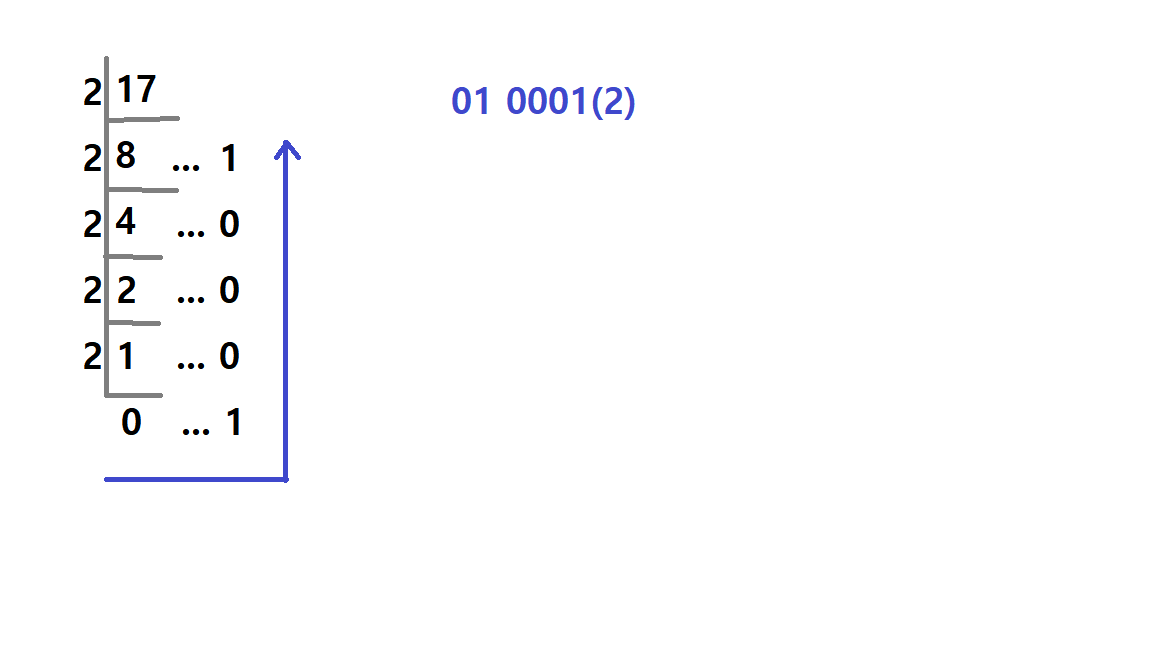
AND : 둘 중 하나라도 0이면 0이다.
0과 OR하면 그대로 나온다. (붙여넣기)
XOR : 1이면 다르고 0이면 같다.
5) 논리 비트 연산자
=> bool 데이터끼리 가지고 연산을 수행해서 결과를 bool로 리턴하는 연산자
and : 둘 다 True인 경우에만 True이고 나머지 경우는 False
or : 둘 다 False인 경우에만 Fasle이고 나머지 경우는 True
not : True이면 False, False이면 True
=> and와 or가 같이 있으면 and가 우선
=> and와 or는 연산자의 좌우를 변경해도 연산의 결과는 그대로 동일하나 과정은 다름
and는 앞의 결과가 false인 경우 뒤의 연산 결과를 확인하지 않습니다.
or는 앞의 결과가 true인 경우 뒤의 연산 결과를 확인하지 않습니다.
-> true에 가까운 것을 or 앞에 배치해야 한다.
-> 결과가 다를 수 있기 때문에 반복문 안에서 사용할 때는 순서를 확인해보고 사용하는 것이 좋습니다.
ex. i = 1 - 100 반복문
1. if i % 3 == 0 and i % 4 == 0:
if i % 3 == 0:
i % 4 == 0
이므로 33번만 반복한다.
2. if i % 4 == 0 and i % 3 == 0:
if i % 4 == 0:
i % 3 == 0
이므로 25번만 반복한다.
6) 논리 함수
all(데이터의 집합) : 데이터의 집합에 있는 모든 데이터가 True이면 True
any(데이터의 집합) : 데이터의 집합에 있는 데이터 중 하나만 True이면 True
Falsy : 0은 False로 간주
-> False(0)이 아닌 것은 전부 True
7) 복합 할당 연산자
변수 연산자 = 데이터 : 변수가 가리키는 데이터와 오른쪽 데이터를 연산자에 해당하는 연산을 하고 그 데이터를 변수가 가리키도록 합니다.
a = 10
a -= 3 # a = a - 3과 동일
a += 3 # a = a + 3과 동일
-> 연산자를 줄였다고 해서 연산자 축약이라고도 한다.
8) 데이터 타입 확인
type(데이터)
9) 참조하고 있는 데이터 확인
id(데이터)
=> id가 같으면 동일한 데이터를 가리키는 것입니다.
a = 10 + 20
b = 30
-> 둘 다 30을 가리키므로 두 개의 id는 같다.
10) 연산자의 우선 순위
=> ., [인덱스]
=> **
=> ~, 부호(+, -)
=> *, /, //, %, @
=> >>, <<(shift)
=> &, ^, |(순서대로 나열함)
=> >, >=, <, <=
=> ==, !=
=> in, not in, is, is not
=> not
=> and
=> or
=> =(할당연산자)
12. 데이터의 자료형 변환(Casting)
=> 다른 자료형끼리 연산을 수행하거나 원하는 결과를 만들어내기 위해서 형 변환을 수행
=> 프로그래밍에서는 일반적으로 숫자와 문자열 사이의 변환이나 문자열과 날짜 사이의 변환을 많이 수행하지만 데이터 분석에서는 이외에도 factor타입으로의 변환이나 문자열 데이터를 비트열로 변환하는 것을 많이 수행합니다.
factor -> 타입 변환을 위해 "제한"을 가한 것임.
1) 형 변환의 종류
=> 묵시적 형변환 : 자동으로 형 변환이 되는 경우
다른 종류의 숫자 데이터끼리 연산을 하는 경우 작은 타입을 큰 타입으로 변환해서 수행
->정수보다는 실수가 크고, 실수보다는 복소수가 크다.
=> 명시적 형변환 : 형 변환을 직접 수행하는 경우
직접 하는 것
정수로 변환 : int(숫자 데이터 또는 숫자로 된 문자열)
실수로 변환 : float(숫자 데이터 또는 숫자로 된 문자열)
bool로 변환 : bool(숫자 데이터 또는 bool로 된 문자열)
문자열로 변환 : str(데이터)
실수를 정수로 변경하면 소수가 소멸됩니다.
Q. 3750을 10의 자리에서 반올림하여 백단위로 변환해봐라.(단, round 함수를 사용해서는 안 된다.)
A. 반올림 하고 싶은 자리를 소수 첫번째 자리로 보낸다. 그 후 0.5를 더하고 소수를 버리면 된다.
-> 3750 / 100 = 37.5
-> 37.5 + 0.5 = 38.0
-> 38 * 100 = 3800
-> int(3750 / 100 + 0.5) * 100 : 3800
13. Console 입출력
1) 콘솔 출력 : print
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
=> 첫번째 매개변수(value)는 출력할 데이터
=> 두번째 매개변수(...)는 출력할 데이터인데 개수 제한이 없음
=> sep는 데이터 사이의 출력되는 문자(데이터 사이에 존재하는 구분자(공백))
=> end는 출력하고 난 후 출력되는 문자
=> file은 출력할 대상을 지정하는 것인데 sys.stdout(표준 출력 장치 - 모니터)
=> flush는 버퍼의 내용을 비울지에 대한 옵션
-> 버퍼는 그냥 메모리로 flush를 사용하면 숫자와 문자를 함께 입출력할 때 생기는 에러나 문제를 해결할 수 있다.
=> 서식 설정
% 다음에 숫자와 영문자 1개를 이용해서 데이터를 포맷에 맞춰서 출력
%10d : 열자리를 확보해서 정수를 출력
%s : 문자열
%d, %i : 정수
%f : 실수
%b : bool 출력
num = 20
print("num은", num) #num은 20
print("num은 %d" %(num)) #num은 20
=> 실수를 출력할 때 .소수자릿수f를 이용하면 출력되는 소수의 자릿수를 설정
=> "{데이터의 인덱스}".format(데이터 나열)
print("{0}은 {1}을 좋아합니다.".format("반승현", "임한별"))
-> 반승현은 임한별을 좋아합니다.
print("{1}은 {0}의 가장 좋아하는 가수입니다.".format("반승현", "임한별"))
-> 임한별은 반승현의 가장 좋아하는 가수입니다.
-> 데이터를 순서에 상관없이 중간중간 끼워 넣을 수 있다.
Memory Leak(누수) : 저장은 했지만 사용을 못하는 상태
ex.
a = 30
a = 20
30에 접근 할 수 있는 방법이 사라짐.
-> "Memory Leak"(보통 문자열에서 많이 발생되고 쓰이는 용어이다.)
** 예외로 변수를 만들고 그 변수를 사용하지 않으면 에러가 생길 수 있다.
=> 따옴표 앞에 f를 추가하면 인덱스 대신에 이름을 사용할 수 있습니다. (f스트링)
singer = "임한별"
fan = "반승현"
print(f"{singer}은 {fan}의 가장 좋아하는 가수입니다.")
2) 콘솔 입력 : input
input(prompt=None, /)
=> prompt는 메시지
=> Enter를 누를 때까지 입력받아서 받은 내용을 하나의 문자열로 리턴합니다.
변수이름 = input('메시지')
=> 정수나 실수 또는 bool을 입력받고자 하는 경우는 형 변환을 이용해야 합니다.
이때 데이터 포맷이 맞지 않으면 예외가 발생합니다.
=> 한 번에 여러 개를 입력받고자 할 떄는 구분 기호를 이용해서 입력받고 split으로 분할하면 list로 만들 수 있습니다.
p.52
연습 문제는 그냥 풀어보자.
14. Git 작업
pycharm - [View] - [Tool Windows] - [Terminal]
1) 로컬 git에 현재 프로젝트를 등록
git init
2) 로컬 git에서 관리할 파일을 등록 (staging)
git add 파일명
ex. git add main.py
현재 디렉토리의 모든 파일을 등록
git add .
=> .gitignoere 파일을 만들어서 파일명이나 디렉토리 이름을 작성하면, 작성된 파일이나 디렉토리는 제외가 됩니다.
3) 변경 내역을 반영
git commit -m "메시지"
------------------------- 로컬 Git 작업
4) 연결 해제
=> 디렉토리 안의 .git 디렉토리를 삭제 (숨김파일 확장을 해야 지울 수 있다.)
5) 자기 branch 확인
git branch
6)branch 생성 및 선택
git checkout -b 브랜치이름
=> -b를 제거하면 브랜치 선택
***** Git 사용법
디렉토리 설정 -> git init -> git add main.py -> git commit -m "메시지" -> git branch
-> git checkout -b master (branch가 마스터가 생성되고 마스터로 옮겨짐)
-> git checkout main(만들 필요는 없고 main으로 브랜치가 옮겨짐)
-------------------------
7) git hub에 연동할 repository를 생성
git hub 접속 -> new -> 이름쓰고 이그노어 설정 -> url 복사 -> -> https://github.com/seunghyeon99/python.git
8) 로컬 git과 repository 연결 - 원본의 이름은 origin을 많이 사용함
git remote add 레포지토리이름 url
확인 : git remote -v
해제 : git remote remove 레포지토리이름
9) 현재까지 작업 내역을 업로드
git push 레포지토리이름 브랜치이름
***** Git 사용법
git remote add origin https://github.com/seunghyeon99/python.git -> git push origin main
10) 변경 내역을 반영하고자 하는경우 2,3,9번 작업만 수행
git add main.py -> git commit -m "~" -> git push origin main
11) 프로젝트 전체 다운로드
git clone url 프로젝트이름
12) 변경 내용을 반영
git pull repository이름 브랜치 이름
13) 브렌치 삭제
git branch -d 브랜치이름
#python
'Python' 카테고리의 다른 글
| 05.OOP(1) (0) | 2023.08.17 |
|---|---|
| 04.Function(2) (0) | 2023.08.16 |
| 04.Function(1) (0) | 2023.08.05 |
| 03.Control Statement (0) | 2023.08.05 |
| 01.Python (0) | 2023.08.05 |