[2] 한 테이블에 많은 수의 칼럼을 가지고 있는 경우
칼럼 수가 많은 테이블에서 데이터 처리를 하게 되면 디스크 I/O의 양이 증가하여 성능이 저하된다.
=> 칼럼 수가 많은 테이블에 대해서는 트랜잭션이 발생될 때 어떤 칼럼에 대해 집중적으로 발생하는지 분석하여 테이블을 분리해주면,
디스크에 적은 칼럼이 저장되므로 로우 체이닝과 로우 마이그레이션이 많이 줄어들고 따라서, 디스크 I/O의 양이 감소하여 성능이 개선된다.
[3] 대량 데이터 저장 및 처리로 인한 성능
데이터의 양이 너무 많으면 서버 사양이 훌륭하고 인덱스를 잘 생성한다고 해도 SQL문장의 성능이 떨어지게 된다.
그래서 논리적으로는 하나의 테이블로 보면서 물리적으로는 여러 개의 테이블 공간에 분리하여 저장할 수 있는 파티셔닝을 적용해야 한다.
- Oracle에서 테이블에 많은 양의 데이터가 예상될 경우
1. RANGE PARTITION(범위)
* 하나의 테이블에 접근하면 내부적으로 RANGE로 구분된 테이블에서 트랜잭션을 처리한다.
가장 많이 사용되는 파티셔닝으로, 대상 테이블이 날짜 또는 숫자 값으로 분리가 가능하고 각 영역(범위) 별로 트랜잭션이 분리될 때 사용한다.
또한, RANGE PARTITION은 데이터 보관 주기에 따라 테이블에 있는 데이터를 지우는 것이 쉬워서 데이터 보관 주기에 따른 테이블 관리에 용이하다. (파티션 테이블을 DROP 하여 데이터를 제거할 수 있다.)
2. LIST PARTITION(특정값 지정)
* 하나의 테이블에 접근하면 내부적으로 LIST로 구분된 파티션 테이블에서 트랜잭션을 처리한다.
대량의 데이터가 있는 테이블에 핵심적인 코드값으로 PK가 구성되어있을 때 값 각각에 의해 파티셔닝을 하기 위해 사용한다.
LIST PARTITION은 대용량 데이터를 특정 값에 따라 분리하여 저장할 수는 있으나, RANGE PARTITION처럼 데이터 보관 주기에 따라 테이블에 있는 데이터를 쉽게 삭제하는 기능은 존재하지 않는다.
3. HASH PARTITION(해시적용)
HASH PARTITION은 지정된 HASH 조건에 따라 해싱 알고리즘이 적용되어 테이블이 분리되며 설계자는 테이블에 데이터가 정확히 어떻게 들어갔는지 알 수가 없다. 또한, 데이터 보관 주기에 따라 테이블에 있는 데이터를 쉽게 삭제하는 기능은 제공되지 않고 오직 성능 향상을 위해 사용한다.
4. COMPOSITE PARTITION(범위와 해시가 복합)
[4] 테이블에 대한 수평 분할/수직 분할의 절차
- 테이블에 대한 수평 분할/ 수직 분할에 대한 결정 원칙
첫 번째. 데이터 모델링을 완성한다.
두 번째. 데이터베이스 용량산정을 한다.
세 번째. 대량의 데이터가 처리되는 테이블에 대해서 트랜잭션 처리 패턴을 분석한다.
네 번째. 어떤 단위(칼럼 단위 혹은 로우 단위)로 집중화된 처리가 발생되는지 분석하여 집중화된 단위로 테이블을 분리하는 것을 검토한다.
제5절 데이터베이스 구조와 성능
[1] 슈퍼 타입/서브 타입 모델의 성능고려 방법
1. 슈퍼 타입/서브 타입 데이터 모델(= 확장(Extended) ER 모델)의 개요
확장 ER 모델이 자주 쓰이는 이유는 데이터의 공통과 차이의 특징을 고려하여 효과적으로 표현하기 때문이다.
공통의 부분을 슈퍼 타입으로 모델링하여 공통의 부분으로부터 상속받고, 다른 엔터티와 차이가 있는 속성에 대해서는 별도의 서브 엔터티로 구분하여 업무의 모습을 정확하게 표현하기 때문에 물리적인 데이터 모델로 변환할 때 선택의 폭을 넓힐 수 있다.
확장 ER 모델은 논리적인 데이터 모델을 분석하는 단계에서 많이 사용되므로 물리적인 데이터 모델을 설계하는 단계에서는 확장 ER 모델을 일정한 기준에 의해 변환해야 한다. (아무런 기준이 없이 변환한다면, 성능이 저하될 위험을 가지게 된다.)
2. 슈퍼 타입/서브 타입 데이터 모델의 변환
- 트랜잭션의 특성을 고려하지 않아 변환 후 성능이 저하되는 경우
1) 트랜잭션은 항상 서브 타입을 개별 테이블로 처리하는데 테이블이 하나로 통합되어 있어서, 불필요하게 많은 양의 데이터가 집약되어 성능이 저하될 수 있다.
2) 트랜잭션은 항상 슈퍼 + 서브 타입을 공통으로 처리하는데 개별로 유지되어 있거나 하나의 테이블로 집약되어 성능이 저하될 수 있다.
3) 트랜잭션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 UNION 연산에 의해 성능이 저하될 수 있다.
# UNION : 중복 행을 한 번만 표시하고 조회된 결과를 합친다.
=> 트랜잭션이 특성을 고려하여 슈퍼/서브 타입 테이블을 설계해야 성능 저하 현상을 예방할 수 있다.
물리적인 데이터 모델을 설계하는 단계에서 변환할 때 고려해야 하는 기준은 데이터의 용량과 해당 테이블에 발생되는 트랜잭션의 유형이다.
3. 슈퍼 타입/서브 타입 데이터 모델의 변환 기술
- 데이터 용량이 클 때, 슈퍼 타입/서브 타입에 대해 논리적인 데이터 모델에서 물리적인 데이터 모델로 변환하는 세가지 유형
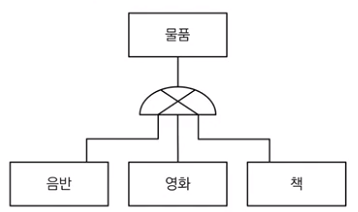
1) 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성 (Roll-Down : One to One Type, 1:1 타입)
업무적으로 발생되는 트랜잭션이 슈퍼 타입과 서브 타입 각각에 대해 발생하는 것이다.
슈퍼 타입과 서브 타입 각각에 대해 독립적으로 트랜잭션이 발생하면, 슈퍼 타입과 서브 타입 모두 꼭 필요한 속성 및 자신의 타입에 맞는 데이터만 가지게 하기 위해서 모두 분리하여 1:1 관계를 만든다. => 데이터 용량이 클 때 디스크 I/O의 양이 증가하는 것을 방지하기 위해 사용한다.
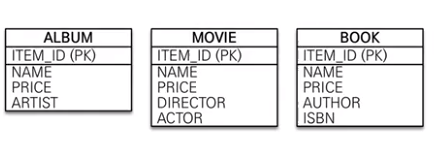
2) 슈퍼 타입 + 서브 타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼 타입 + 서브 타입 테이블로 구성 (Identity : Plus Type, 슈퍼 + 서브 타입)
슈퍼 타입과 서브 타입을 묶어 트랜잭션이 발생하는 특징을 가지고 있을 때, 슈퍼 타입 + 각 서브 타입을 하나로 묶어 별도의 테이블을 구성하는 것이 효율적이다.

3) 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성 (Roll-Up : Single Type, All In One 타입)
테이블을 하나로 묶을 때 각 속성 별로 제약사항을 정확하게 지정하지 못하더라도 데이터 용량이 크고 성능 향상을 위해 하나의 테이블로 구성한다.
데이터를 통합하여 처리할 때(테이블을 하나로 묶을 때) 테이블을 개별로 분리하면 불필요한 조인을 유발하거나, UNION ALL과 같은 SQL구문이 작성되어 성능이 저하된다.
# UNION ALL: 중복 행을 모두 표시하고 조회된 결과를 합친다.

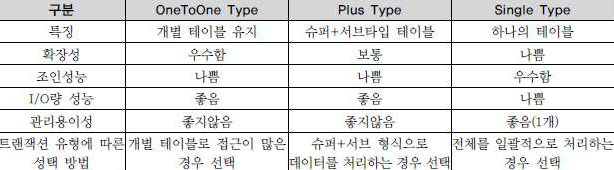
4. 슈퍼 타입/서브 타입 데이터 모델의 변환타입 비교
[TISTORY] 공부하는 개발자 핑구(출처 링크 댓글)
[데이터 전문가 포럼] SQL 개발자 스터디 교재(2020.08.22.)
#SQLD